
Are you using RAG agents yet? Read this before you decide
Retrieval-Augmented Generation (RAG) connects language models to enterprise knowledge stores, retrieving verified information before generating responses.
TLDR: RAG systems reduce AI hallucinations from 30-40% to under 6% by grounding answers in actual documents, making them accurate enough for production use in compliance, legal, and operational workflows.
Leaders across industries are adopting this approach quickly. Gartner predicts that by 2026, 40% of enterprise applications will include task-specific agents, up from under 5% in 2025.
For instance, Morgan Stanley”s wealth management division deployed an AI assistant that answers advisor questions by retrieving from 100,000 research reports. First, the system retrieves relevant research. Then, it generates answers grounded in that content. When advisors ask about Fed rate hikes or IRA procedures, the system delivers answers from the firm’s knowledge base instantly.
The impact is dramatic. In Healthcare RAG Hallucination Study, conventional chatbots showed 40% hallucination rates. In contrast, RAG-based systems reduced this to 0-6%, depending on the model and source quality.
This pattern now appears across sectors. Importantly, these aren’t experiments, they’re production workflows handling decisions that need verifiable accuracy.
What is RAG
Retrieval-Augmented Generation connects language models to enterprise knowledge stores. Instead of relying solely on what the model learned during training, RAG systems retrieve relevant documents, database records, or policy text at query time, then use that retrieved context to generate responses.
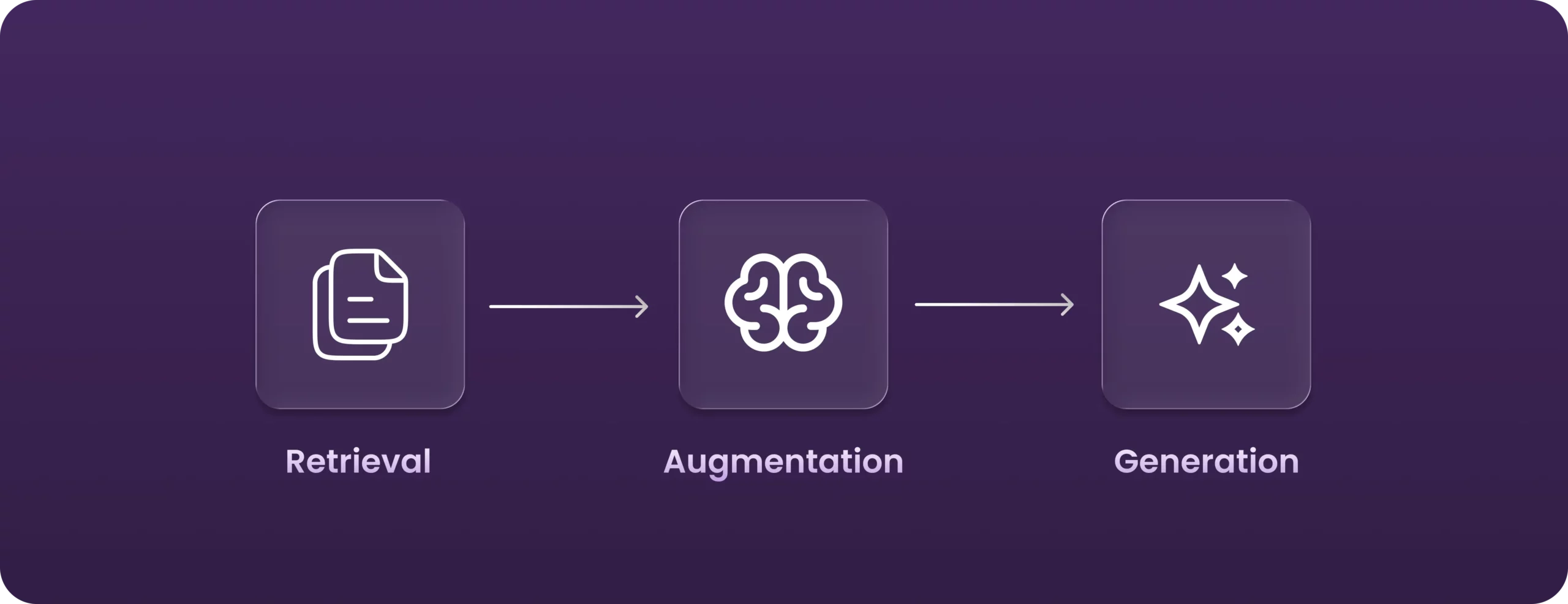
The architecture has three core components:
- Retrieval layer that finds relevant information
- Context assembly process that packages what was found
- Generation layer that produces answers grounded in that context
Traditional language models generate responses from patterns learned during training. Those patterns reflect broad internet-scale data, not the specific contracts, policies, procedures, and records your enterprise depends on.
When someone asks about your company’s severance policy or the warranty terms in a supplier agreement, a base model has no way to access that information. It will guess, and those guesses often sound confident even when they’re wrong.
RAG systems don’t guess. They look it up first.
What this means: RAG agents act as bridges between language models and your enterprise knowledge, ensuring every answer is grounded in verified documents rather than model training data.
How RAG reduces hallucinations
RAG reduces hallucinations by giving the model actual source material before it generates a response. Instead of inventing information based on training patterns, the model references specific documents, contract clauses, or policy sections that were retrieved at query time.
Without retrieval, language models hallucinate plausible-sounding answers roughly 30% of the time. With retrieval-augmented generation, that drops below 3%.
Does RAG eliminate hallucinations entirely?
Straight answer? No. RAG dramatically reduces hallucinations but doesn’t eliminate them.
In legal research conducted by Stanford, conventional AI tools hallucinated between 17% and 33% of the time, even with RAG methods. That’s still a significant improvement over base models, which fail far more frequently—but it means RAG outputs still require validation mechanisms.
What this demonstrates: RAG makes AI accurate enough for production use in high-stakes workflows, but not accurate enough to remove human oversight entirely.
Where does RAG still fail?
To avoid failure, it’s best to understand what can cause RAG to fail:
- Retrieval returns wrong documents – If the retrieval layer surfaces irrelevant content, the model generates answers from incorrect context
- Context windows overflow – Critical details can fall outside token limits when queries require reviewing hundreds of pages
- Knowledge is outdated – Stale indexes generate answers from superseded policies or contracts
What this means? It has less to do with RAG itself than it does with its configuration. We’ll soon demonstrate how to navigate these concepts as well.
Real-world validation example
Dropbox built Dash with RAG plus multi-step agent planning so employees can ask for “notes for tomorrow’s all-hands” and get dates resolved, meetings located, docs retrieved, and logic checked before the final response.
This demonstrates that RAG agents can turn search into finished work rather than just document discovery, but only when retrieval, validation, and assembly are properly orchestrated.
This means, building RAG agents requires investing in retrieval quality, citation verification, and observability, not just connecting a model to a vector database.
Exploring AI Agents? Here’s 30 agents to draw inspiration from, including agent stories from Uber, Finch, and more!
Where enterprises see the value of RAG
As we’ve established already, RAG systems reduce hallucination errors in high-stakes work. For example, when a compliance officer checks export control procedures, a retrieval-grounded answer tied to policy documents differs fundamentally from a generated guess.
Additionally, RAG surfaces information across disconnected systems. A procurement analyst can query one RAG interface for pricing trends, instead of searching through invoices, contracts, and emails separately.
Furthermore, RAG scales expert access. When 50 people need tax guidance, a RAG system lets them self-serve from internal sources. As a result, they avoid waiting for specialist review.
The operational gain is speed and stability. Queries that previously took hours of manual research now complete in seconds, with citations that allow verification.
Measurable impact
At Morgan Stanley, document access jumped from 20% to 80%, and salespeople using their RAG-based research tool take one-tenth of the time to respond to client inquiries compared to traditional methods.
What this demonstrates: RAG agents deliver value through speed AND accuracy, not by replacing human judgment, but by giving humans faster access to verified information.
Data quality at scale: Delivery Hero’s quick commerce team uses agentic AI to extract 22 product attributes and standardize titles with confidence scoring and human review for low-confidence outputs.
What this demonstrates: RAG-powered agents can fix messy real-world catalog data at production scale when paired with proper confidence thresholds and human review loops.
What this means: The ROI case for building RAG agents comes from workflow acceleration with maintained accuracy, not from headcount reduction.
Understanding the RAG spectrum
Not all enterprise search and generation systems work the same way. Understanding where different approaches sit on the automation spectrum helps clarify what RAG is, and what it isn’t.
| Approach | How it works | Enterprise use case | Key limitation |
| Keyword search + manual review | User searches documents, reviews results, synthesizes answer | Legal research, compliance review | Slow, doesn’t scale to high query volumes |
| Semantic search + summarization | Retrieves documents using vector embeddings, generates summary | Initial document discovery | Requires human validation of accuracy |
| Retrieval-Augmented Generation | Retrieves context, generates responses with citations | HR policy, contract analysis, regulatory Q&A | Quality depends on retrieval precision |
| RAG agent | Orchestrates retrieval, validates sources, and generates with citations and confidence scores | Multi-step compliance workflows, supplier analysis | Requires governance framework and observability |
| Multi-agent RAG | Specialized agents coordinate across knowledge stores with domain-specific reasoning | Financial exposure analysis across systems | High orchestration complexity |
| Fine-tuned models | Knowledge encoded in model weights, no retrieval | High-speed inference for static knowledge | Expensive to update, no source tracking |
Most enterprises start with semantic search plus summarization, then move to building RAG agents when they need verifiable, citation-backed answers.
RAG agents appear in workflows where a single query requires pulling from multiple systems. Salesforce’s Horizon agent translates natural language into reliable SQL, enriches questions with dataset context, and posts results back in Slack with explanations for trust.
What this demonstrates: Building RAG agents with proper governance enables “ask the data” workflows that respect access control and provide audit trails.
What this means: The path from basic RAG to production RAG agents requires adding orchestration, validation, and governance layers, not just better retrieval.
Building RAG agents: Single-agent vs multi-agent architectures
In simple terms: Single-agent RAG struggles with questions that require pulling from multiple systems with different data types. Multi-agent RAG splits retrieval and reasoning across specialized agents.
Single-agent RAG architecture
One agent handles the entire workflow:
- Receives query
- Retrieves relevant documents
- Assembles context
- Generates response with citations
Best for: Focused use cases like contract analysis or policy Q&A where knowledge is centralized in one system.
Example: A compliance officer asks “What’s our data retention policy for customer emails?” The RAG agent retrieves the policy document, quotes relevant sections, and provides citations.
What this demonstrates: Single-agent RAG works when retrieval requirements are straightforward and all knowledge lives in one place.
Multi-agent RAG architecture
Specialized agents coordinate on complex queries:
- Supervisor agent plans the research strategy
- Worker agents search different knowledge stores simultaneously
- Validation agent evaluates factual accuracy and citation quality
- Synthesis agent combines findings into coherent answers
Best for: Complex queries spanning heterogeneous data sources (structured databases, unstructured documents, live APIs).
Example: Anthropic’s research agent demonstrates this pattern. A supervisor plans the approach, spawns workers to search, and uses an LLM judge for accuracy scoring before synthesis.
What this demonstrates: Multi-agent reasoning catches retrieval errors and conflicting information before presenting answers to users.
This article by Microsoft provides criteria to help you decide whether to build single-agent or multi-agent systems across your organization.
Real-world implementation: Supplier risk assessment
A single query “What’s our risk exposure to Supplier X?” triggers:
- Contract agent: Retrieves terms, payment schedules, obligations
- Financial agent: Pulls payment history, credit ratings, financial statements
- Logistics agent: Checks delivery performance, shipping data, quality metrics
- Synthesis agent: Combines findings, flags conflicts, generates risk assessment with confidence scores
- Validation agent: Verifies citations, checks for outdated data, ensures access controls were respected
What this demonstrates: Building multi-agent RAG systems enables workflows that were previously impossible to automate—but only when orchestration and governance are properly designed.
What this means: Most enterprises should start with single-agent RAG and only move to multi-agent architectures when queries genuinely require specialized reasoning across heterogeneous sources.
Agent autonomy models for RAG systems
In simple terms: As you build RAG agents, you must decide what actions they can take independently versus when they must ask for human approval.
| Autonomy Level | Agent Behavior | Use Case | Escalation Trigger |
| Level 1: Assisted | Retrieves and presents options; human decides | Initial RAG pilots, sensitive compliance queries | All decisions require human approval |
| Level 2: Recommended | Retrieves, analyzes, and recommends; human approves | Policy Q&A, contract search | Low confidence scores (<0.7) |
| Level 3: Conditional | Retrieves, decides, and acts within thresholds | Internal knowledge, HR queries | Conflicting sources, permission boundaries |
| Level 4: Adaptive | Adapts retrieval strategy based on result quality | Multi-system procurement analysis | Strategy changes, unusual patterns |
| Level 5: Autonomous | Full workflow autonomy with learning loops | (Rare in enterprise; mostly research) | System-defined edge cases |
Where to start when building RAG agents
Most enterprise RAG agent deployments operate at Level 2-3 autonomy.
Financial services and healthcare typically cap at Level 2 due to regulatory requirements.
Internal knowledge systems can safely reach Level 3-4 with proper guardrails.
Real-world example: Uber’s Finch agent operates at Level 3 autonomy. It routes financial queries to specialized sub-agents, generates SQL, validates results, and returns answers—all without human intervention. However, it escalates to Level 2 (human review) when:
- Query results seem anomalous compared to recent patterns
- Multiple data sources return conflicting metrics
- The requesting user lacks full access to all relevant data marts
What this demonstrates: RAG agents enable governed self-service without widening access risk when autonomy levels are properly calibrated to use case sensitivity.
What this means: Define agent autonomy levels before building. Start at Level 2, measure escalation rates and accuracy, then advance autonomy only when governance infrastructure supports it.
Where RAG systems fail
Retrieval quality determines answer quality
If the retrieval layer returns irrelevant documents, the model generates responses from the wrong context. A query about “data retention requirements” might retrieve marketing content about customer data instead of legal retention schedules, leading to completely inaccurate guidance.
Solution pattern: Anthropic’s research agent plans, spins up worker agents to search, and uses an LLM judge for factual and citation accuracy scoring before final answers. Multi-stage validation catches retrieval errors before they reach users.
What this demonstrates: Building production RAG agents requires validation layers, not just better retrieval algorithms.
Context window limits create hard constraints
Most models accept between 32,000 and 200,000 tokens of input. If a query requires reviewing 500 pages of related documents, the system must decide what to include and what to discard. Those decisions introduce risk. Critical details can fall outside the context window.
What this means: When building RAG agents for document-heavy workflows, implement smart chunking strategies and relevance ranking—don’t just dump everything into the context window.
Citation accuracy isn’t guaranteed
A model can claim a statement comes from a specific document while actually paraphrasing loosely or combining information from multiple sources. Users need tooling to trace answers back to exact passages.
Quality gate example: Intercom ships an end-to-end voice agent stack for phone support that handles real calls with transcription, text-to-speech, knowledge grounding, and quality gates, with playbooks on achieving 75%+ AI resolution rates and clean escalation paths.
What this demonstrates: Building trustworthy RAG agents requires programmatic citation verification, not just formatted references.
Access control breaks down if retrieval ignores permissions
A RAG system that pulls from all indexed documents might surface confidential HR records to employees who shouldn’t see them, or expose restricted financial data to unauthorized users. Retrieval must respect the same access policies as the underlying systems.
Uber’s Finch agent demonstrates proper implementation—it keeps access under RBAC and curated data marts, ensuring finance teams only see metrics they’re authorized to query.
What this demonstrates: Building enterprise RAG agents requires integrating with identity providers and policy stores from day one, not retrofitting permissions later.
Knowledge drift creates silent failures
If the document index isn’t refreshed when policies change or contracts are amended, the system generates answers grounded in outdated information. Without observability into retrieval freshness, teams operate on stale data without realizing it.
What this means: Building maintainable RAG agents requires automated reindexing workflows and freshness monitoring—not one-time vector database loads.
Should you build a RAG agent? Decision matrix
You should build a RAG agent if:
✓ Accuracy matters more than creativity – Compliance, legal, finance workflows where wrong answers have consequences
✓ Answers must be traceable – Regulatory environments requiring audit trails and source citations
✓ Knowledge lives in internal systems – Contracts, policies, procedures not available in public training data
✓ Queries are repetitive – Same 50-100 questions asked across teams, consuming specialist time
✓ Access control is critical – Different users need different views of the same knowledge base
You should avoid building RAG agents if:
✗ Tasks are open-ended or creative – Marketing copy, product naming, strategic brainstorming
✗ Source documents are unreliable – Inconsistent, outdated, or contradictory knowledge bases
✗ You cannot maintain retrieval freshness – No capacity for automated reindexing or quality monitoring
✗ Governance infrastructure doesn’t exist – No RBAC, audit logging, or approval workflows in place
✗ The problem is actually search – Users just need better document discovery, not AI-generated answers
What this means: Most enterprises have 5-10 high-value use cases where building RAG agents delivers clear ROI. Start there before expanding.
Enterprise RAG architecture
A production RAG system needs several components to operate reliably in enterprise environments.
Document ingestion pipeline
Processes source documents, applies chunking strategies that preserve semantic coherence, and generates vector embeddings. Must handle updates and deletions without breaking retrieval quality. Tracks document versions and metadata.
Vector database or search index
Stores embeddings and enables fast similarity search. Needs to scale to millions of documents without degrading query latency. Should support filtered search so retrieval respects access control policies.
Access control integration
Enforces permissions at retrieval time. If a user can’t access a document in the source system, they shouldn’t see it in RAG results. Requires integration with identity providers and policy stores.
Context assembly logic
Decides which retrieved documents to include in the model’s context window, in what order, and with what framing. Must balance relevance, diversity, and token limits.
State management example: Airtable’s field agents run as an event-driven state machine with context manager, tool dispatcher, and decision engine for summarization and content ops across bases. This architecture blueprint works for structured, low-drift agent actions in content and CRM operations.
Prompt engineering layer
Constructs the final prompt sent to the language model, including retrieved context, the user’s query, and instructions for citation and formatting.
Citation and source tracking
Links generated responses back to specific documents, passages, or database records. Enables users to verify claims and trace reasoning.
Observability and logging
Captures which documents were retrieved for each query, what was included in context, and what was generated. Essential for debugging poor answers and identifying retrieval quality issues.
Feedback and evaluation systems
Tracks user ratings, measures retrieval precision, and monitors hallucination rates. Feeds into continuous improvement of chunking, embedding, and ranking logic.
What this means: Building production RAG agents is an infrastructure project, not a model feature you turn on. Budget accordingly.
RAG governance and risk controls
RAG systems introduce new failure modes. However, each has specific mitigations.
Retrieval poisoning
If an attacker injects malicious content into indexed documents, the RAG system will retrieve and use that content in responses. To prevent this, organizations need document provenance tracking, access control on ingestion pipelines, and periodic content audits.
Citation fabrication
A model might generate plausible citations that don’t actually exist in retrieved documents. Therefore, systems need programmatic verification that citations map to real passages, not just user trust.
Context leakage
Retrieved documents might contain sensitive information. Consequently, systems must enforce access control at retrieval time and redact content based on user permissions.
Outdated information
If the retrieval index isn’t refreshed when source documents change, answers reflect stale data. As a result, systems need automated reindexing workflows triggered by document updates, plus metadata that tracks content freshness.
Over-reliance on retrieval
If the retrieval layer returns poor results, the model generates answers from irrelevant context. Nevertheless, users may trust the response because it includes citations. Thus, systems need retrieval quality scoring, confidence thresholds, and clear signaling when confidence is low.
Real-world example: Delivery Hero implements human review for low-confidence outputs in their catalog agents. This approach builds trust without blocking automation entirely.
What this demonstrates: Building safe RAG agents requires accepting that some queries won’t be answerable, and signaling that clearly rather than generating plausible-sounding wrong answers.
Governance frameworks must specify:
- Who can query which knowledge stores
- What types of questions are in scope vs. out of scope
- How often indexes are refreshed
- What citation standards apply
- When human review is required before acting on RAG outputs
- How retrieval quality is measured and improved
- What happens when a query can’t be answered from available sources
- At what autonomy level each agent type operates
- How multi-agent workflows escalate conflicts or low-confidence results
How to build and deploy RAG agents
Start with high-value, low-risk use cases
Begin where accuracy is critical and knowledge is concentrated in structured repositories. Regulatory compliance Q&A, internal policy guidance, and contract analysis are strong early targets. Avoid open-ended creative tasks or queries that require judgment beyond what documents contain.
Internal knowledge wins: Moveworks’ Brief Me lets employees upload PDFs and docs, then summarize, compare, and query them inside chat, backed by an agentic architecture that improves knowledge access without changing systems.
What this demonstrates: Building RAG agents for internal knowledge access delivers ROI faster than customer-facing deployments because risk tolerance is higher and iteration cycles are shorter.
Build the retrieval pipeline first
Invest in document ingestion, chunking strategies, and vector search infrastructure before optimizing generation quality. Poor retrieval defeats even the best language models.
What this means: Spend 70% of your initial effort on retrieval quality and 30% on prompt engineering, not the reverse.
Integrate access control from day one
Don’t build a system that works for unrestricted users and retrofit permissions later. Design retrieval to respect the same policies as source systems.
Instrument everything
Log queries, retrieved documents, generated responses, and user feedback. RAG quality degrades silently, you need observability to detect when retrieval precision drops or citation accuracy declines.
Set clear thresholds for trust vs. escalation
Not every query is answerable from available documents. The system should signal uncertainty rather than guess.
Define agent autonomy levels early: Start at Level 2 (recommended actions with human approval), measure escalation rates and accuracy, then advance autonomy only when governance infrastructure supports it.
Plan for knowledge maintenance
Document repositories change constantly. Build automated reindexing workflows and monitor content freshness. Stale indexes create compounding risk over time.
Measure impact on workflow speed and decision confidence
Track how RAG affects decision-making velocity and accuracy, not just query volume. The value of building RAG agents is in enabling faster, more accurate decisions, not in replacing human judgment entirely.
Expand to multi-system retrieval incrementally
Agent-based workflows that retrieve from databases, APIs, and document stores simultaneously introduce complexity that should be managed after single-source RAG is stable.
Consider multi-agent reasoning only after single-agent RAG proves reliable. The orchestration overhead isn’t worth it unless queries genuinely require specialized reasoning across heterogeneous sources.
What this means: Most enterprises should plan for 3-6 months to go from pilot to production with a single-agent RAG system, then another 3-6 months before attempting multi-agent architectures.
What this shift means for enterprises
RAG isn’t a model feature you turn on. Instead, it’s infrastructure you build, govern, and maintain. Enterprises that treat building RAG agents as infrastructure projects get verifiable, citation-backed answers they can act on. In contrast, those that don’t get expensive hallucination engines with extra steps.
Meanwhile, the next evolution is already visible: multi-agent RAG systems that use specialized reasoning across knowledge domains. These systems don’t just retrieve, they orchestrate parallel retrieval workflows, apply domain-specific reasoning, and synthesize findings under unified governance.
Three paths forward for building RAG agents
Path 1: Enhanced single-agent RAG
One agent with sophisticated retrieval strategies, dynamic re-ranking, and adaptive chunking. Best for focused use cases like contract analysis or policy Q&A where knowledge is centralized. Operates at Level 2-3 autonomy.
Path 2: Multi-agent retrieval orchestration
Specialized agents for different knowledge stores (contracts, emails, databases) coordinated by a supervisor agent. Enables complex queries that span systems while maintaining clear ownership and audit trails. Each agent operates at its appropriate autonomy level with clear escalation paths.
Path 3: Autonomous reasoning networks
Agents that not only retrieve but debate, validate, and refine answers through multi-agent reasoning. A contract agent might challenge a compliance agent’s interpretation, forcing both to cite sources and resolve conflicts before presenting to users. Requires Level 4+ autonomy with extensive governance.
Your roadmap for building RAG agents
For enterprises ready to move beyond pilots:
- First, start with single-source RAG in high-value workflows at Level 2 autonomy
- Next, build governance and observability infrastructure for safe production deployment
- Then, experiment with multi-agent reasoning for queries that require cross-system retrieval
- Finally, advance agent autonomy levels incrementally based on measured performance and escalation rates
Ultimately, companies investing in RAG pipeline quality, access control, retrieval observability, and agent autonomy frameworks today are building the foundation for trusted AI systems. Conversely, companies skipping those steps are building systems that fail quietly, and expensively.
What this means: The competitive advantage goes to enterprises that treat building RAG agents as a multi-quarter infrastructure initiative, not a sprint to deploy the latest model.
Build RAG agents with DronaHQ
DronaHQ’s AI agent builder is designed for production RAG deployments. Teams can connect retrieval agents to existing document stores, vector databases, knowledge bases, and internal systems without rebuilding infrastructure. Built-in autonomy controls let you define decision thresholds, escalation rules, and human-in-the-loop checkpoints.
This makes it easier to pilot one high-value workflow, measure hallucination reduction, and scale gradually with built-in governance, without managing a research stack.
See RAG agents in action: Schedule a call with our team to explore how retrieval agents and multi-agent reasoning fit into real business operations.
Related Articles