How engineering teams deploy AI coding agents at scale
Engineering teams already know AI can help write code. The larger shift is that agents can now carry work across more of the SDLC. That changes the unit of value from “generated code” to “work moved through the delivery system with less manual translation.” This article is about how to adopt that model in a way that works inside the stack teams already have.
AI coding agents already have a place in engineering teams. Code generation is one obvious use. Test generation, code review, and refactoring are others. The larger opportunity starts when those agents are no longer treated as one-off helpers and start participating across the software delivery path.
A feature request enters one system, decisions get made in another, implementation happens in the repo, validation runs in CI, and review happens somewhere else again. When that path stays loose, teams spend time translating the same piece of work from one stage to the next. Agentic SDLC keeps that work connected as it moves.
From isolated help to connected delivery
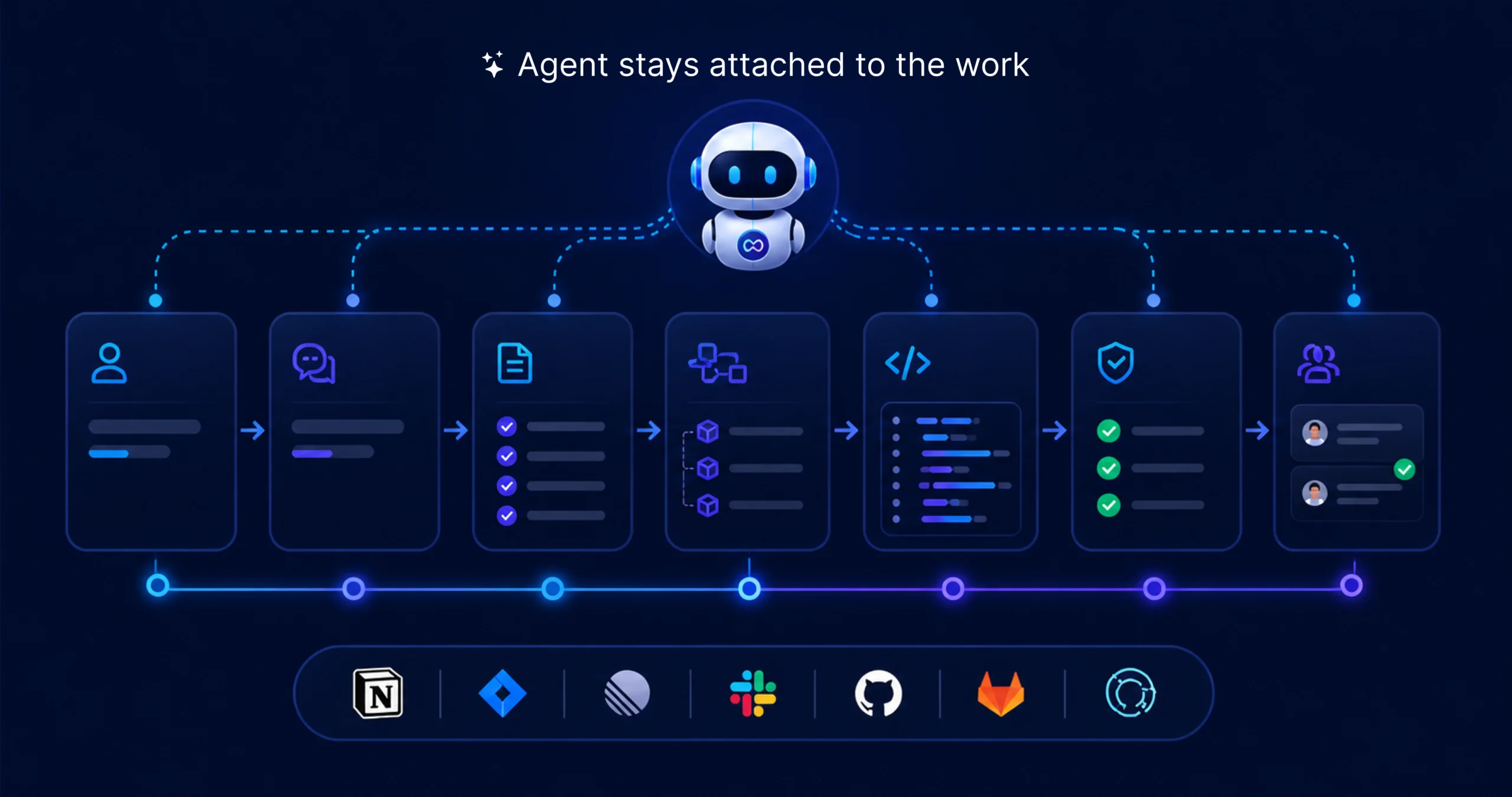
Agentic SDLC is a workflow where the agent stays attached to the work as it moves.
A feature or bug does not stay as a loose ticket waiting for a developer to interpret it from scratch. The request is clarified before implementation begins. A PRD or structured requirement document captures the user flow, acceptance criteria, technical direction, and scope. That work becomes an issue, then breaks into smaller slices that can move through branches, validation, and review while carrying their context forward.
The point is not to make every team follow one fixed stage model. Different teams will run different paths. The important part is continuity. The request, the requirement, the implementation slices, and the review context stay connected instead of being recreated manually at each step.
That is why this can work inside an existing stack. Intake can stay in Notion, Jira, or Linear. Clarifications can happen in Slack. Code can continue moving through GitHub or GitLab. Validation can stay in the CI flow the team already trusts.
One feature, tracked cleanly
Start with one internal app and one small feature. A greeting-message setting in an admin panel – requirement mentioned in simple words.
Here is the workflow in clean steps.
- The request lands in the team’s tracker. It could begin in Notion, Jira, or another system where the team already captures feature work.
- The agent asks follow-up questions before implementation starts. It needs to know what triggers the message, where it appears, who can edit it, whether the content is static or generated, and what should happen if the message source fails.
- Those answers turn into a PRD. The document captures the user flow, acceptance criteria, technical approach, scope, and out-of-scope.
- The PRD becomes a main issue. That issue is then split into smaller pieces.
- The work is decomposed into slices. One slice may handle the settings UI. Another may handle configuration or API behavior. A third may cover validation and fallback logic.
- Dependencies are mapped before branches multiply. Independent slices can move in parallel. Dependent slices can be sequenced.
- Review happens against linked context. The reviewer sees what was requested, what was decided, what changed, and what already passed validation.
A broken status filter in an internal ops dashboard or a permission toggle in a settings screen would follow the same pattern. The feature changes. The tracking path stays recognizable.
Where the workflow gets stressed
The first pressure point is the request itself. A vague request becomes expensive the moment the workflow starts operationalizing it. Clarification, scope boundaries, user journeys, and acceptance criteria belong upstream for that reason.
The second pressure point is decomposition. A single feature often becomes several coordinated slices before it reaches review. Hidden dependencies make branch activity look busy while making merge order harder to trust.
The third pressure point is review context. A diff without linked requirement history, changed-file intent, and validation status forces the reviewer to reconstruct the task by hand. That burns exactly the attention the workflow is supposed to protect.
The fourth pressure point is deployment order. A UI change may depend on a back-end update. A flag may need to land before behavior changes. A schema change may need to precede downstream logic. Sequence belongs inside the workflow.
Where Code Factory fits
Code Factory is built for this kind of workflow.
It supports the path across intake, clarification, BRD or PRD creation, issue creation, branch creation, review support, merge support, and status visibility. A request can start in Notion or Jira. Clarifications can move through Slack. Repos and merge requests can stay in GitHub or GitLab. Validation can continue through the CI setup already in place.
The stack stays in place. The structure between its parts gets tighter.
If your team is moving in that direction, explore DronaHQ’s agent-native software development approach.
Read more
Related Articles