
Chunking strategies for RAG pipelines: A practical guide for 2026
A support agent answers a customer’s question confidently. The answer is wrong. The right document was in the knowledge base. The retrieval system found it. But the chunk that reached the language model had been split mid-paragraph, cutting off the condition that changed everything.
That failure is not a model problem. It is a chunking problem.
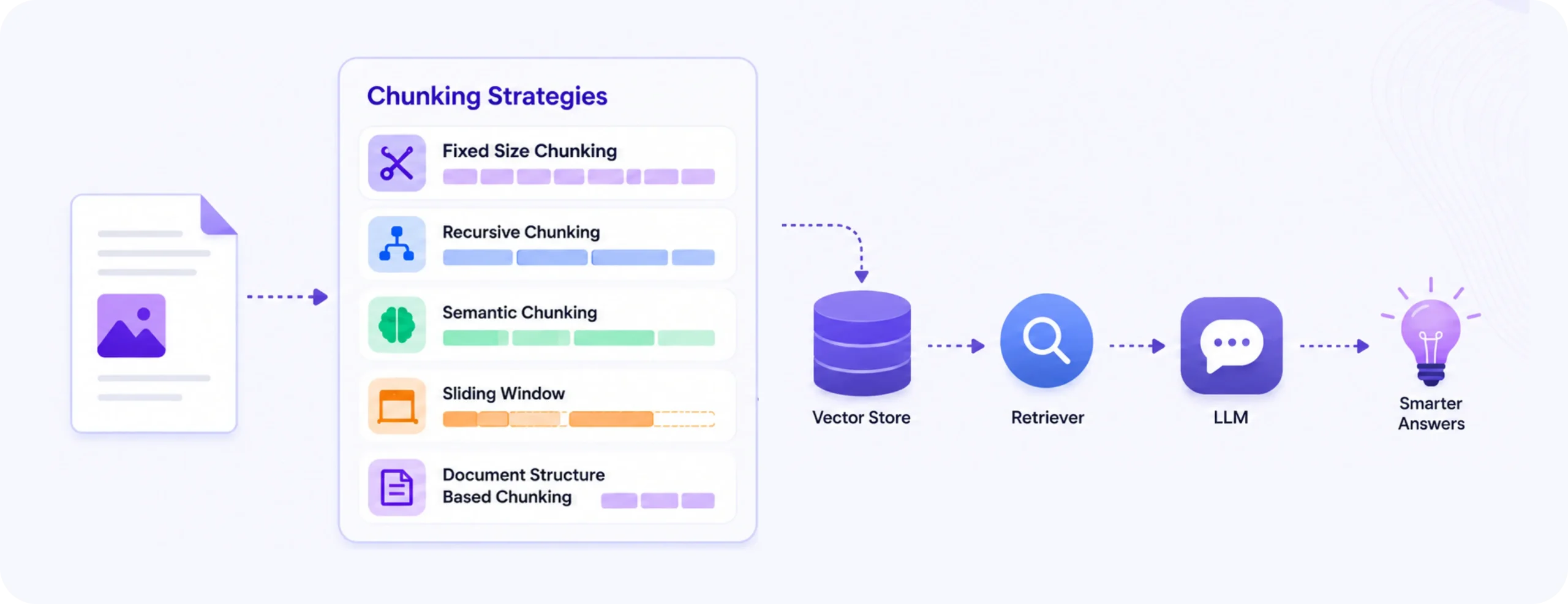
TL;DR: Chunking strategies for RAG determine how documents are split before indexing. The wrong strategy causes retrieval failures, incomplete answers, and higher hallucination rates. This guide covers 7 chunking strategies: fixed-size, recursive, sentence splitting, semantic, document-structure-aware, parent-child, and late chunking, with guidance on when to use each in production.
Why chunking decisions have real business consequences
Enterprises are betting heavily on RAG. 51% of enterprise AI implementations now use RAG architecture, and the RAG market is projected to reach $9.86 billion by 2030, growing at 38.4% CAGR. Yet 70% of enterprise RAG deployments fail before they reach production.
The gap between demos and production is well-documented. 71% of organisations report regular GenAI use, but only 17% attribute more than 5% of EBIT to it. The engineering gap is real, and a 40% retrieval failure rate has been cited across multiple 2024 and 2025 production retrospectives.
Much of that failure traces back to how documents are split before indexing.
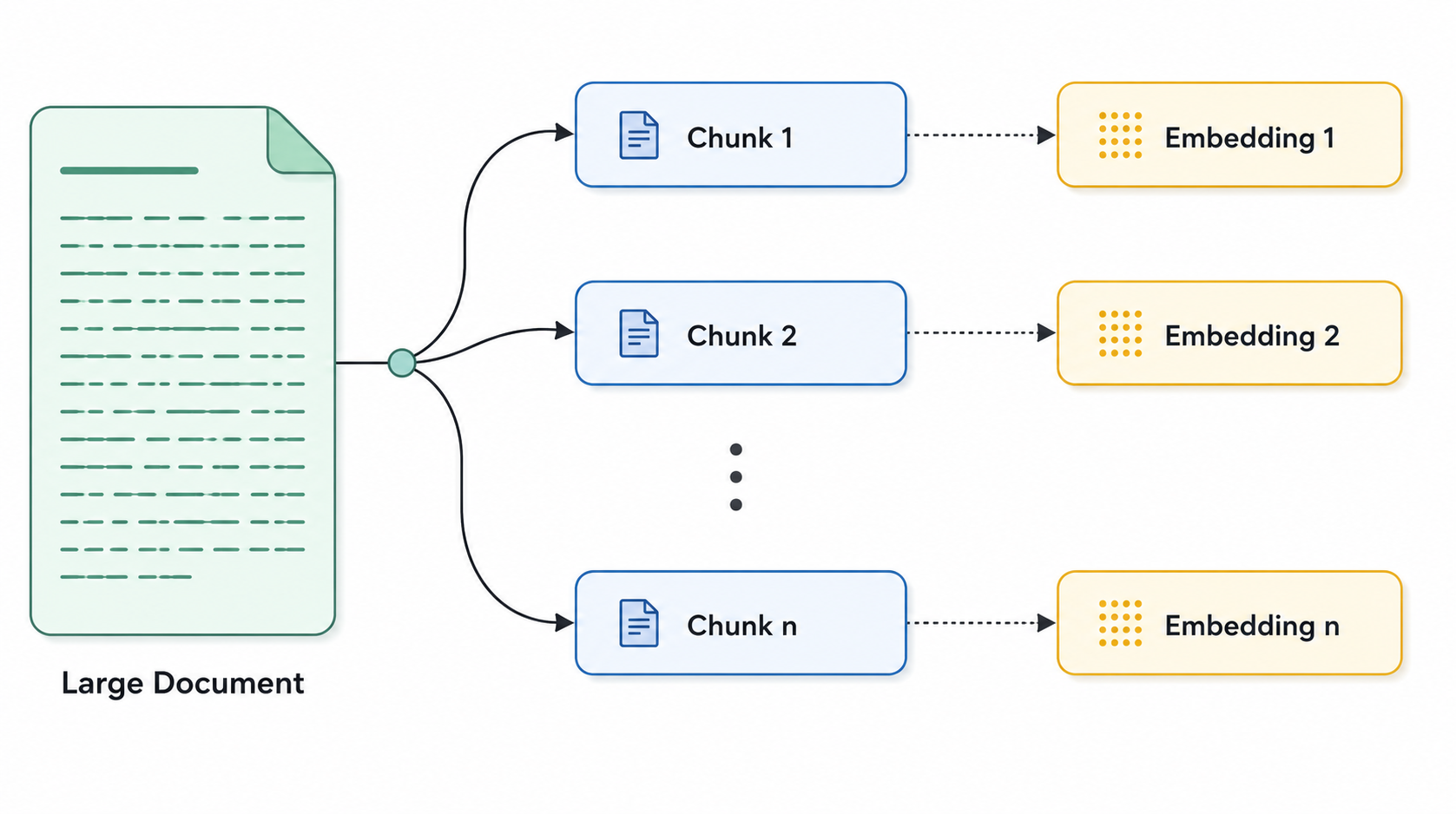
Chunking is the process of breaking documents into smaller segments before they are embedded and stored in a vector database. The size, content, and boundary of each chunk determines how well the system retrieves relevant information and how well the language model reasons over it.
Get it wrong and you get retrieval noise, incomplete answers, higher hallucination rates, and inflated token costs. Get it right and the whole pipeline becomes more accurate, faster, and cheaper to run.
Why 2026 is the year to get chunking strategies for RAG right
Three things have converged to make chunking strategy more consequential than it was two years ago.
First, RAG has moved from internal tools to customer-facing applications. The tolerance for retrieval errors is lower. A knowledge base chatbot giving a wrong answer to an employee is annoying. The same system giving a wrong answer to a regulated financial or healthcare customer is a liability.
Second, enterprises are now running RAG across 30 to 60% of their AI use cases, which means chunking decisions that were made during a pilot affect far more downstream systems than they did originally.
Third, research has caught up. A 2026 cross-domain study benchmarking 36 segmentation methods found that content-aware chunking significantly outperforms fixed-length splitting, with the top strategy achieving a mean nDCG@5 of approximately 59%, compared to under 24.4% for naive fixed-size character chunking. The evidence now clearly shows which approaches work and under what conditions.
The core tension every RAG builder faces
Before choosing a strategy, it helps to understand what you are balancing.
Retrieval accuracy favours smaller, focused chunks. A chunk that captures one clear idea produces a precise embedding. That makes it easier for vector search to match it against a user query.
Generation quality favours larger, more complete chunks. Once a chunk is retrieved, the language model needs enough context to produce a coherent answer. A single sentence pulled from the middle of a technical document often means nothing on its own.
These two goals pull in opposite directions. The chunk that is ideal for retrieval is often too short for generation. The chunk that gives the model full context is often too noisy for retrieval to surface reliably.
There is a second problem layered on top of this. Even when retrieval succeeds, large context inputs degrade model performance. MIT and Google Cloud AI researchers identified a U-shaped attention bias in LLMs, where tokens at the beginning and end of the input receive higher attention regardless of their relevance — the “lost in the middle” effect. This positional bias has been confirmed across retrieval, summarisation, and question-answering tasks. Passing oversized chunks to the model makes this worse.
The goal is to find the balance point: chunks small enough for precise retrieval, complete enough for coherent generation.
The following comparison of chunking strategies for RAG helps identify the right approach based on document type, retrieval needs, and production constraints.
Chunking strategy comparison: choose by use case
Use this chunking strategies for RAG comparison table to match your document type to the right approach.
| Strategy | Best document type | Retrieval precision | Generation context | Implementation effort | When to avoid |
| Fixed-size | Unstructured, mixed | Low–Medium | Low | Very low | Structured docs, regulated content |
| Recursive | Articles, blog posts, reports | Medium | Medium | Low | Highly structured or tabular data |
| Sentence splitting | Conversational, transcripts | Medium–High | Medium | Low | Long technical documents |
| Semantic | Policy docs, research, knowledge bases | High | High | Medium | Tight latency budgets, simple corpora |
| Document-structure-aware | Markdown, HTML, code, PDFs | High | High | Medium | Unstructured prose without markup |
| Parent-child (hierarchical) | Long reports, legal docs, manuals | Very high | High | Medium–High | Short documents or single-topic files |
| Late chunking | Agentic systems, query-heavy workloads | Very high | Very high | High | Batch ingestion pipelines, static corpora |
Pre-chunking vs post-chunking: the architectural decision that comes first
Before choosing a specific strategy, you need to decide when chunking happens.
Pre-chunking is the default. Documents are split into chunks before embedding, then stored in the vector database. All chunks are pre-computed. Retrieval is fast because everything is already indexed.
The trade-off is that pre-chunking requires upfront decisions about chunk size and boundaries that are made without knowing what queries will look like. A chunk split that seemed reasonable during ingestion may not serve the actual queries users send.
Post-chunking takes the opposite approach. Full documents are embedded first. At query time, only the retrieved documents are chunked, and only on demand. This avoids processing documents that are never queried. It allows the system to adapt chunking decisions based on what the query actually needs.
The trade-off is latency on first access and more complex infrastructure. Retrieved results can be cached, so the system improves over time as frequently accessed documents build up a chunk cache.
A useful rule of thumb: use pre-chunking for stable, well-understood corpora where retrieval patterns are predictable. Consider post-chunking for agentic systems or high-variance query environments where document relevance is harder to predict at ingestion time.
7 chucking strategies for RAG, explained by use case
1. Fixed-size chunking: where to start, not where to stay
Fixed-size chunking splits text into segments of a predetermined length, typically measured in tokens or characters. It is the easiest approach to implement and the right place to get a baseline.
The limitation is that it ignores the structure of the document entirely. It will cut a sentence in half, split a code block mid-function, or separate a policy clause from its condition. This creates retrieval noise and generation gaps.
Chunk overlap is the key lever here. Repeating 10 to 20% of tokens from the end of one chunk at the start of the next preserves boundary context without significantly increasing storage costs. An overlap below 10% often loses critical connective information. Above 25% and you are paying for redundancy that adds noise more than it helps.
Use this for: quick prototyping, unstructured mixed content where document type is unclear, establishing a baseline before investing in more complex strategies.
Do not use this for: structured documents, regulated content where sentence completeness matters, anything where a half-sentence answer would be worse than no answer.
2. Recursive chunking: the sensible default for most text
Recursive chunking uses a priority list of separators — double newlines first, then single newlines, then sentences, then words. It tries the highest-priority separator first. If a resulting chunk is still too large, it applies the next separator to that chunk only.
This approach respects the document’s natural organisation. Paragraphs stay together. Sections do not get arbitrarily split. The output is more coherent than fixed-size chunks, with similar implementation simplicity.
Use this for: articles, blog posts, research papers, customer support documents, any general prose where documents have consistent paragraph structure.
Do not use this for: highly structured documents with tables, numbered sections, or code, where the separators it relies on do not map to meaningful boundaries.
3. Sentence splitting: precision for conversational and transcript content
Sentence splitting uses NLP boundary detection to split at natural sentence endings. Each chunk contains one or more complete sentences with no mid-sentence breaks.
This is valuable when the content is dialogue-heavy or when each sentence carries a distinct piece of information. Support transcripts, customer feedback records, and interview notes are good candidates.
The limitation is uneven chunk sizes. A technical document might have sentences of 8 words and sentences of 60 words. The short ones may lack context. The long ones may carry too much noise.
Use this for: conversational data, call transcripts, customer reviews, FAQ content where each answer is a self-contained unit.
Do not use this for: long technical documents, legal text, or any content where meaning depends on the relationship between consecutive sentences.
4. Semantic chunking: grouping by meaning, not by character count
Semantic chunking uses embedding models to measure the semantic similarity between adjacent sentences. When similarity drops significantly between two sentences — indicating a shift in topic — the system creates a chunk boundary there.
This produces chunks that align with actual conceptual boundaries in the document rather than arbitrary size limits. The result is higher retrieval precision because each chunk represents a coherent idea.
The cost is real, though. Every sentence must be embedded to compute similarity, which adds processing time and embedding API cost during ingestion. For large corpora, this can be a significant overhead.
One nuance worth knowing: a benchmark by Qu et al. (2024) found that the choice of embedding model had a larger measurable effect on retrieval quality than the chunking strategy itself. If you are running semantic chunking on a weak embedding model, you are solving the wrong problem.
Use this for: policy documents, knowledge bases, research content, dense technical documentation where topic boundaries are important.
Do not use this for: tight latency budgets where ingestion speed matters, or simple corpora where sentences are short and topics are consistent throughout.
5. Document-structure-aware chunking: let the format guide the split
This strategy reads the document’s inherent structure — headings, subheadings, code blocks, HTML tags, Markdown sections — and uses those as natural chunk boundaries.
A Markdown article with H2 headings naturally segments into topics. An HTML page with <section> tags defines its own logical divisions. A Python file with class and function definitions chunks cleanly by logical unit.
For PDFs specifically, a preprocessing step is required. PDFs are a visual format. Columns, tables, and scanned pages make raw text extraction unreliable. Converting PDFs to structured Markdown before applying this strategy is the most reliable approach for enterprise document libraries.
Use this for: technical documentation, product manuals, HTML knowledge bases, code repositories, PDF documents that have been converted to clean text.
Do not use this for: unstructured plain text without markup, legacy documents that have not been cleaned or formatted.
6. Parent-child (hierarchical) chunking: retrieval precision with generation context
This is one of the most effective strategies for long enterprise documents, and one of the most underused.
The approach works in two layers. Small child chunks — typically 100 to 200 tokens — are created for embedding and retrieval. These short chunks produce precise, query-aligned embeddings. But when a child chunk is retrieved, the system returns its parent chunk — a larger section of 500 to 1,000 tokens — to the language model.
This means retrieval benefits from precision, and generation benefits from full context. The two goals are no longer in conflict.
The approach works particularly well for long structured documents where the relevant passage is a small part of a larger section that is required for the answer to make sense. A legal contract clause. A policy exception. A technical specification buried in a product manual.
Use this for: legal documents, compliance manuals, product documentation, annual reports, any content where relevant passages only make sense in the context of their surrounding section.
Do not use this for: short documents, single-topic files, or corpora where every chunk is already context-complete on its own.
7. Late chunking: query-time splitting for agentic systems
Late chunking inverts the normal order. Instead of chunking documents before embedding them, the full document is embedded first to preserve long-range semantic dependencies. Chunking then happens at the point of retrieval, applied only to the documents that were actually retrieved.
The practical implication is that phrases like “the city” or “its policy” carry their referent entity’s meaning through the embedding, even when the entity was mentioned several sentences earlier. Naive chunking breaks that connection. Late chunking preserves it.
The trade-off is infrastructure complexity and first-access latency. Cached results reduce the latency issue over time, but the initial setup cost is higher than any of the other strategies.
Use this for: agentic systems where queries are highly variable, knowledge bases with dense cross-referencing, workloads where entity resolution accuracy is critical.
Do not use this for: batch ingestion pipelines that need to process millions of documents quickly, or static corpora where all queries are known in advance and pre-chunking can be optimised upfront.
Chunk overlap: the lever most teams underuse
Overlap is not a strategy on its own, but it affects every strategy above.
Adding overlap — repeating a portion of one chunk at the start of the next — reduces the risk of splitting related information across boundaries. The standard guidance is 10 to 20% of the chunk size.
Below 10% and you frequently lose the connecting context that ties adjacent ideas together. Above 25% and you increase storage costs, introduce retrieval noise from duplicate content, and push more tokens into the LLM unnecessarily.
For recursive and fixed-size strategies, overlap is the fastest improvement most teams can make without changing their architecture. For parent-child and semantic strategies, overlap matters less because the boundary logic already preserves context.
What chunking decisions affect downstream
It helps to think about chunking not as a one-time ingestion step, but as a design choice with multiple downstream effects.
Hallucination rate. Providing the model with precise, relevant chunks grounds its response in actual source content. Noisy or incomplete chunks make hallucination more likely because the model is working from insufficient context.
Retrieval recall vs. precision. Smaller chunks improve precision — the right chunk is more likely to match a specific query. But recall can suffer if a chunk contains only part of the information needed to answer a multi-part question. Parent-child strategies address this directly.
Token cost. Every token passed to the model costs money. Oversized chunks that contain irrelevant content inflate token usage on every query. Right-sized chunks reduce cost per query at scale.
Latency. Smaller chunks mean fewer tokens to process. For high-throughput enterprise applications, this difference compounds quickly.
Enterprise guidance: what to do before scaling
Enterprise teams evaluating chunking strategies for RAG should treat chunking as a tunable system parameter rather than a fixed preprocessing step.
Segment your document library by type first. Different document types have different structural properties. A support transcript should not be chunked the same way as a compliance manual. Route document types to the strategies that fit them. This is more reliable than trying to find one strategy that works across everything.
Establish a baseline with fixed-size chunking before optimising. It is the fastest way to identify where the pipeline breaks. Once you have baseline retrieval metrics, you can isolate the effect of changing chunking strategy from the effect of changing embedding models or retrieval parameters.
Evaluate retrieval accuracy before changing chunking strategy. Qu et al. (2024) found that embedding model selection had a larger impact on retrieval quality than chunking strategy in their benchmarks. If retrieval is poor, check your embedding model before assuming the chunking strategy is the problem.
Monitor what gets retrieved, not just what gets answered. Answer quality is a lagging signal. Retrieval accuracy — measured by whether the right document and the right chunk were in the top K results — is more diagnostic and easier to act on.
Set token budgets per document type. For an enterprise with a mix of short FAQ entries, long policy documents, and structured product sheets, a single token budget for all chunks is a poor fit. Type-specific budgets give each content category the right retrieval characteristics.
Plan for freshness. Stale chunks are among the most common production RAG failures. A document gets updated. The old chunks stay in the index. Vector similarity keeps returning the outdated version because its language is still a good match. Build re-ingestion triggers into document update workflows before this becomes a support escalation.
How DronaHQ approaches chunking
Most platforms pick one strategy and apply it uniformly. DronaHQ uses a hybrid approach that adapts to the document structure.
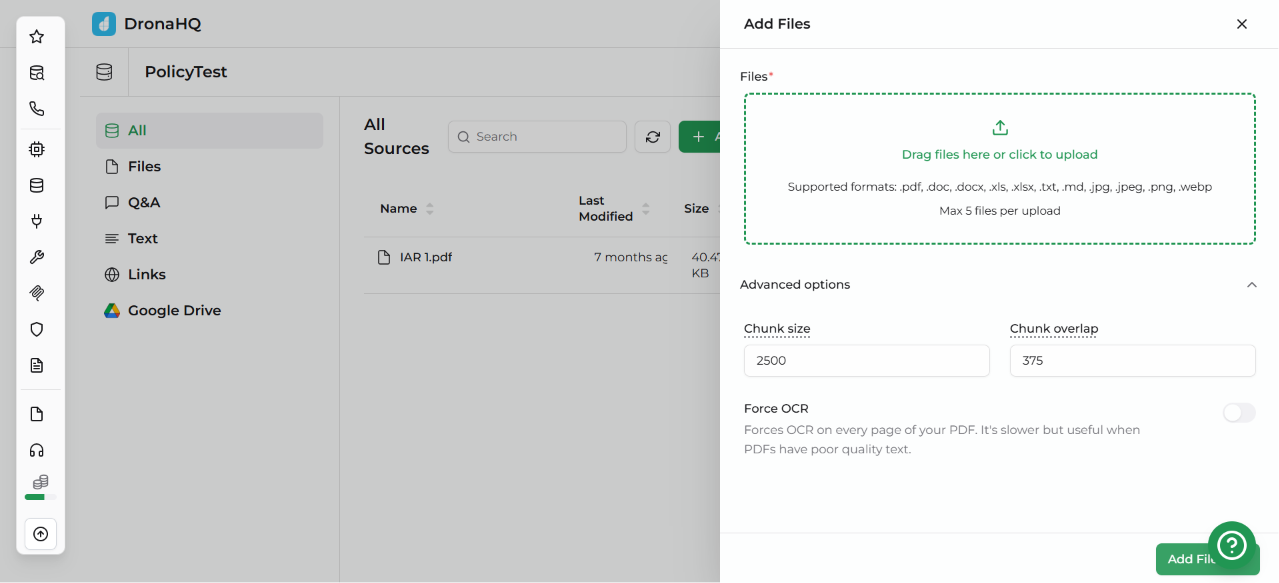
- Preprocesses documents before chunking: Every uploaded document first goes through a document processing and OCR layer that converts PDFs and other formats into clean, structured text, ensuring chunking starts with high-quality input.
- Uses structure-aware chunking by default: Documents are initially split based on their natural hierarchy (headings and sections), with each chunk retaining its associated heading. Preserving this context improves embedding quality and helps retrieval models better understand the topic of each chunk.
- Falls back to recursive chunking when needed: If a section remains too large after the initial split, DronaHQ applies recursive chunking only to that section. It progressively splits content using logical separators (paragraphs, lines, then sentences) instead of breaking text arbitrarily.
- Allows configurable chunk size and overlap: Chunk size and overlap are configurable during document upload rather than being fixed. The default overlap is 15%, striking a balance between preserving context across chunk boundaries and avoiding unnecessary storage overhead or retrieval noise.
- Improves retrieval with reranking: After semantic search retrieves the most relevant chunks based on embedding similarity, DronaHQ applies an enterprise-grade reranking model to reorder the results before they are sent to the language model. This retrieve-then-rerank approach improves precision by prioritizing the chunks that are most likely to answer the user’s query, rather than relying solely on vector similarity.
Where this is heading
The boundary between chunking and retrieval is dissolving. Future of chunking strategies for RAG is moving toward query-aware and dynamic segmentation rather than static preprocessing. Late chunking points toward a world where the system decides, at query time, what the right chunk boundaries are for that specific question. Research into query-aware segmentation, where documents are re-chunked dynamically based on what is being asked, is active and producing early results. For enterprises building RAG systems now, the practical priority is to make chunking strategy a documented, testable variable rather than a fixed configuration that gets set once and forgotten.
Related Articles

