
Do you actually need a vector database for RAG?
Most teams asking whether they need a vector database for RAG are asking the question too late in the stack. The better question comes first. What kind of retrieval problem are you actually solving?
The short answer is no. Most RAG systems do not need a dedicated vector database on day one. You need one when semantic retrieval across unstructured content becomes central to the product, and when scale, latency, and filtering complexity have outgrown simpler options.
If your data is small, structured, or precision-heavy, a search engine, SQL query, or lightweight hybrid setup may do the job. A dedicated vector database starts to earn its place when semantic retrieval, scale, and metadata-aware filtering become central to the product.
That distinction matters because teams often start with infrastructure before they have proved the retrieval problem. They set up embeddings, add a vector store, wire up retrieval, and assume they now have a serious RAG system. Then the results come back noisy, irrelevant, or hard to trust. At that point, the temptation is to swap models, change chunk sizes, or try another database. In many cases, the real issue sits one layer deeper. The retrieval design was never thought through properly.
This article is a practical decision guide. It looks at when a vector database is genuinely useful, when simpler approaches are enough, where Graph RAG fits, why hybrid retrieval often ends up being the production answer, and what retrieval architecture makes sense for the kind of AI product you are building.
The mistake most teams make with RAG
RAG is often introduced as a clean sequence. Take your data, split it into chunks, generate embeddings, store them in a vector database, retrieve similar chunks, and pass them into the model.
That flow is easy to teach. It is also why so many teams assume a vector database is mandatory.
What gets lost in that simplified narrative is that retrieval is not one problem. It is a series of decisions. You have to think about how the data is structured, how users ask questions, whether exact matches matter more than semantic similarity, whether permissions shape the answer set, whether explainability matters, and whether you are searching across a few thousand records or tens of millions of chunks.
When teams skip those questions and jump straight to a vector database, they often build a system that retrieves something, but not necessarily the right thing. The prototype looks impressive in a demo. Production is where the cracks appear.
You start seeing policy answers that quote the wrong section. Support agents retrieve old troubleshooting steps. Internal search brings back semantically similar text that is less useful than an exact keyword match would have been. None of this automatically means vector search is bad. It usually means the retrieval architecture was treated as a default instead of a design choice.
Why vector databases became the default answer
Part of the reason is timing. RAG became popular at the same time as embedding models and vector databases became more accessible. Tutorials, frameworks, and vendor ecosystems all reinforced the same mental model. If you are building RAG, you need embeddings. If you have embeddings, you need a vector database.
That mental shortcut spread because it was useful enough to feel right. Semantic retrieval is an important breakthrough. A model can find relevant information even when the user does not know the exact keyword. That is genuinely useful.
The problem is that a useful default became a dogma. Many teams now reach for vector infrastructure before they have verified that their workload actually needs it.
Why that default leads to overengineering
A vector database adds real complexity. You now have embedding pipelines, indexing strategies, chunking decisions, sync jobs, freshness concerns, relevance evaluation, and another production system to monitor.
That complexity makes sense only when it solves a problem you have already seen in the product.
If your knowledge base is small, if the important terms are explicit, if your users search by product code or policy name, or if your workflow can call systems directly, vector search may be solving the wrong problem in an elegant way.
Data freshness problem (or the “sync” tax)
Before you commit to a dedicated vector store, you need to account for the Sync Tax. Unlike a relational database, where a row is available the millisecond it’s written, a vector database requires a constant embedding pipeline.
Every time your source data changes, a policy is updated or a ticket is closed, you have to re-chunk the text, re-generate the embedding via an API, and re-index the vector store. If your application requires real-time data freshness, the complexity of keeping your Postgres records and your Vector Store in sync can become a significant DevOps burden. If you don’t have a strategy for “Incremental Indexing,” your AI will be confidently giving users yesterday’s news.
What problem is a vector database actually solving?
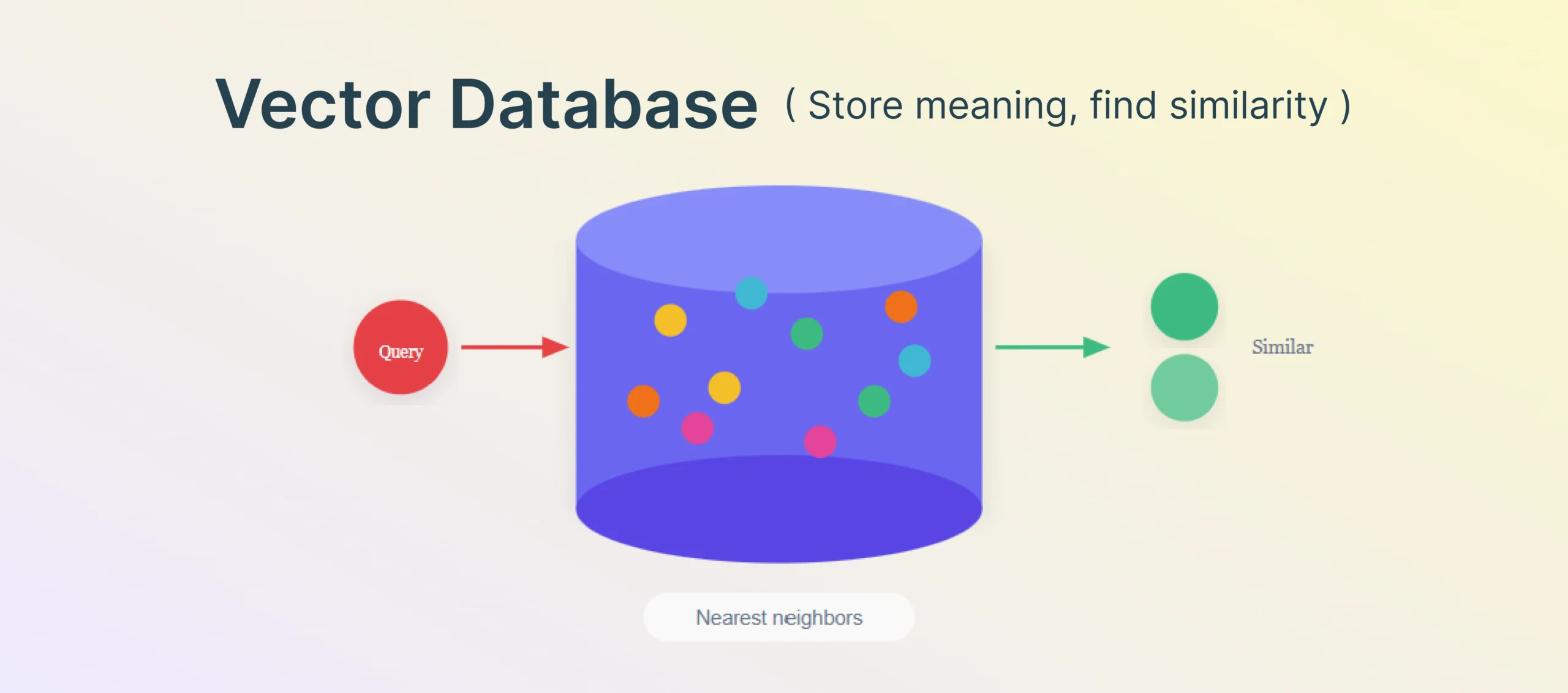
A vector database is built to store and search embeddings efficiently. In practice, that means it helps retrieve items that are semantically similar to a given query, even when the words do not match exactly.
That is valuable in environments where the same idea can be expressed many different ways. A support ticket may describe the same issue with different wording. Internal documentation may explain the same process across multiple pages. A user may ask a natural-language question without knowing the official terminology.
In these cases, semantic retrieval can outperform exact-match search because it helps bridge the gap between user phrasing and document phrasing.
Why “Vector search” doesn’t mean “Accurate answers”
One of the biggest traps teams fall into is treating a vector database like a magic relevance box. In reality, semantic retrieval is a game of Recall vs. Precision.
Vector databases are built for high recall—they are excellent at finding everything that is “mathematically similar” to your query. But in production, you usually need high precision. Because most vector stores rely on Approximate Nearest Neighbor (ANN) algorithms, they trade off a bit of accuracy for massive speed. If your RAG system is hallucinating, it’s often because the retrieval step provided a “similar” chunk that was actually factually irrelevant.
When semantic retrieval is genuinely useful
Semantic retrieval becomes especially useful when your content is unstructured and language-heavy. Internal wikis, meeting transcripts, support conversations, product documentation, research notes, and knowledge bases are common examples.
It is also useful when users ask fuzzy questions. A user may ask, “Why are invoice approvals getting delayed?” while the relevant documentation talks about approval thresholds, exception handling, and department-level routing rules. A keyword-only search may miss the connection. Embedding-based retrieval has a better chance of surfacing the right material.
Another good fit is a corpus large enough that browsing it or structuring it by hand stops being realistic. At that point, approximate nearest-neighbor search and specialized indexing start to provide real value.
What a vector database does not solve by itself
This is where expectations often drift away from reality.
A vector database does not decide how to chunk your data. It does not know whether your chunks are too broad, too narrow, outdated, duplicated, or stripped of useful context.
It does not enforce business logic. It does not understand that a policy from last year should rank below the current one. It does not know which sources are authoritative. It does not explain why a chunk was retrieved. It does not fix weak query formulation. It does not automatically protect sensitive information with the right permission checks.
It also does not remove the need for hybrid retrieval. In production, semantic similarity alone is often too loose. Teams usually need some combination of lexical search, metadata filters, reranking, recency logic, and permissions-aware access to make retrieval trustworthy.
Most importantly, it does not guarantee useful answers. Retrieval quality depends on the whole system around it, not on the storage layer alone.
When you probably do not need a vector database yet
Many teams can stay simple far longer than they think.
Your data is small and stable
If your corpus is small, a dedicated vector database may be unnecessary. You can often generate embeddings, store them in a lightweight setup, and run similarity search directly in memory or inside an existing database.
Many teams overestimate how quickly they will hit real retrieval scale. They design for millions of chunks before they have even proved that users are asking questions that require semantic search.
If your content changes rarely and your dataset is limited, simplicity is often the better engineering choice.
Your data is mostly structured
If the answer lives in tables, records, statuses, IDs, or well-defined fields, this is usually not a vector-search problem. It is a lookup problem.
Customer data, order status, invoice values, approval states, shipment details, employee records, and transaction histories are better served by direct system queries, relational databases, and filters.
Trying to use semantic retrieval for structured facts can reduce precision and introduce failure where none needed to exist.
Exact matches matter more than semantic similarity
Many production workloads care more about exactness than about broad semantic overlap.
If a user is searching for an error code, policy clause, SKU, contract term, compliance requirement, or product name, lexical search is often more trustworthy. Exact phrase matches, keyword weighting, filters, and metadata ranking can outperform semantic search in these cases.
This is one reason enterprise search often benefits from hybrid approaches. A purely vector-based setup may retrieve text that feels related while missing the precise item the user actually needed.
You have not proved that retrieval is the bottleneck
Sometimes teams say they need a vector database when what they really have is a content problem or a workflow problem.
The issue may be poor documentation structure. It may be weak prompts. It may be that the model is being asked to do system actions that should be deterministic API calls. It may be that the data needs metadata filters, not better embeddings.
If retrieval has not been isolated as the actual bottleneck, adding infrastructure is often just adding noise.
When a vector database starts to make sense
There are, of course, cases where a vector database clearly earns its keep.
You have large volumes of unstructured text
Once your system needs to search across a growing body of documentation, transcripts, tickets, reports, and notes, semantic retrieval becomes more attractive. Users will not know the exact phrasing buried inside that corpus. They will ask in their own language.
At that point, a vector database can help retrieve relevant context efficiently and consistently.
Users ask fuzzy or natural-language questions
If your product is designed around open-ended questions rather than exact lookup, semantic retrieval matters more.
This is common in AI copilots, internal knowledge assistants, support agents, and research workflows. Users are not going to type exact document titles. They are going to ask what they need in plain language.
When the wording varies and meaning matters more than exact terms, vector search becomes valuable.
You need scalable similarity search with acceptable latency
A prototype can tolerate inefficient retrieval. A production product cannot.
As the corpus grows, brute-force search becomes too slow and difficult to maintain. Dedicated vector systems offer indexing and search optimizations built specifically for approximate nearest-neighbor retrieval.
That matters when relevance and latency both influence user trust.
You need hybrid retrieval and metadata-aware filtering
This is usually the point where production requirements start to bite.
Most useful retrieval systems do not rely on semantic similarity alone. They combine similarity with source filters, date filters, user-level permissions, customer account boundaries, document types, product lines, regions, or recency logic.
Once those requirements become central, dedicated retrieval infrastructure can start to justify itself.
RAG is not one thing. Choose the retrieval architecture that fits the job
A better way to think about this is through retrieval architectures, not RAG as one standard pattern.
Option 1. Search engine first
If your data is keyword-heavy, precision matters, and you need explainable ranking, a search engine may be the right first step.
This works especially well for policy search, help centers, product documentation, compliance content, and operational knowledge where exact matches or weighted term relevance matter.
A strong search engine setup can also be easier to debug. You can see why results ranked the way they did, tune relevance more directly, and combine keyword matching with filters cleanly.
Option 2. Postgres plus pgvector
If your team already runs on Postgres, adding vector search through pgvector can be a smart intermediate step.
It lets you experiment with semantic retrieval inside an existing data stack, without introducing a separate vector platform too early. For many teams, this is enough for the first serious version of RAG.
It is not the perfect long-term answer for every workload. It is valuable because it keeps complexity proportional to the problem.
Option 3. Dedicated vector database
This starts to make sense when semantic search is core to the product, the corpus is large, the latency requirements are stricter, and indexing or filtering needs go beyond what lighter setups can handle comfortably.
At that stage, dedicated vector systems offer specialized infrastructure that can improve performance and operational clarity.
The key phrase is “at that stage.” Not before.
Option 4. Knowledge graph or Graph RAG
Some problems are not primarily about retrieving similar text. They are about following relationships.
Who approved this exception. Which account owns this resource. What systems depend on this service. Which entities are connected through a chain of events.
In those cases, relationship-aware systems and graph-based reasoning can become more useful than pure similarity search.
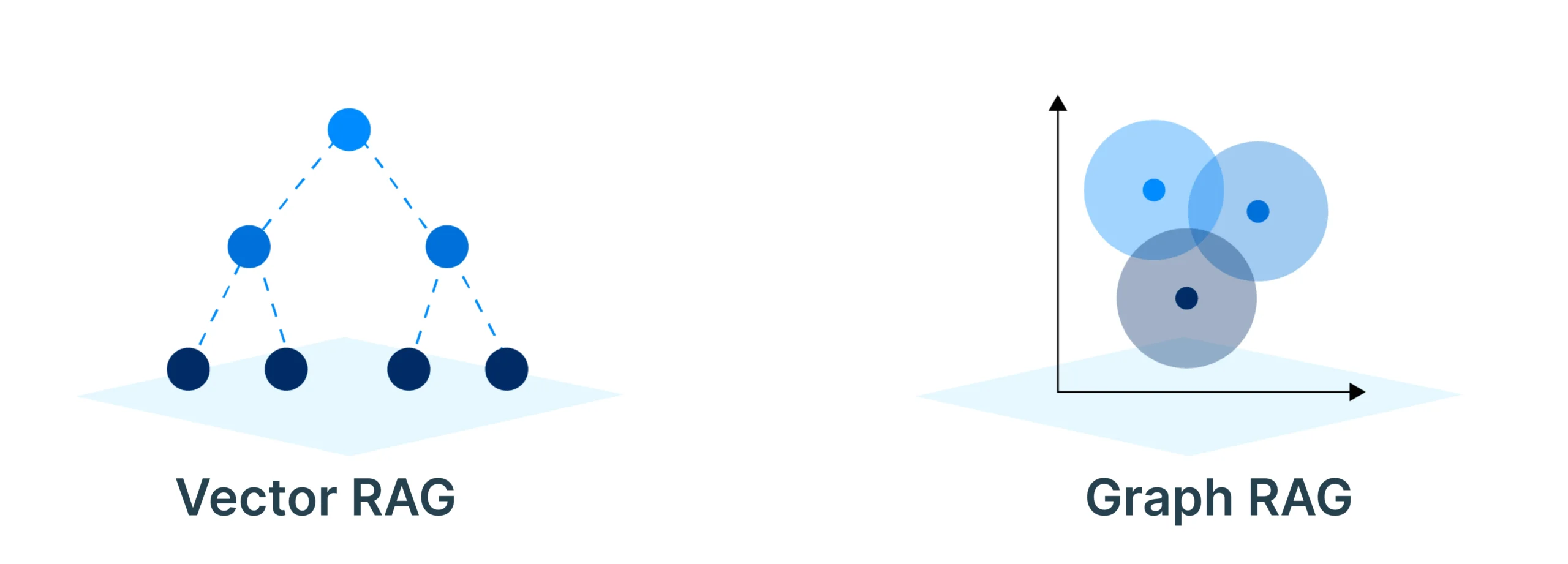
Graph RAG vs Vector RAG
This comparison gets a lot of attention, but it is often framed too loosely.
When Vector RAG is enough
If your main task is retrieving relevant text from unstructured content, Vector RAG is usually enough.
It works well for document-heavy workflows where the goal is to find passages, summaries, answers, or supporting context based on semantic similarity.
For many support, knowledge, and documentation use cases, this is the correct tool.
When Graph RAG earns the added effort
Graph RAG becomes more valuable when the answer depends on relationships between entities, not just on which chunks look semantically similar.
Fraud investigations, lineage tracking, complex approvals, dependency mapping, enterprise knowledge maps, and cross-system reasoning often fall into this category.
The gain is not just better retrieval. It is more structured reasoning over how things connect.
Why hybrid approaches are becoming more common
In practice, many production systems end up combining approaches.
A graph may help model entities and relationships. Vector retrieval may help search unstructured documents. Lexical search may help when exact terms matter. Reranking may help sort the final candidates.
That is closer to how real retrieval stacks evolve than the idea that one database choice solves everything.
A practical decision framework
If you are deciding what to build, ask these questions before choosing your retrieval stack.
Ask these 7 questions before choosing your retrieval stack
- Is my data mostly structured, mostly unstructured, or a mix of both?
- Do users search with exact terms, or do they ask fuzzy natural-language questions?
- Does precision matter more than recall in this use case?
- How large is the corpus today, and how fast will it grow?
- Do I need permissions-aware retrieval, metadata filters, or recency controls?
- Does the answer depend on relationships between entities?
- Have I proved that retrieval, and not content quality or workflow design, is the real bottleneck?
These questions will usually tell you more than a product feature checklist.
Quick decision guide
Use this as a first-pass map from problem type to retrieval architecture.
| Situation | Best starting point |
| Data is structured and lives in systems of record | Direct SQL queries, APIs, and filters |
| Queries depend on exact terms like IDs, SKUs, clauses, or error codes | Search engine or lexical search |
| Content is unstructured and users ask natural-language questions | Semantic retrieval with embeddings |
| Team already runs on Postgres and wants a lightweight first version | Postgres plus pgvector |
| Semantic retrieval is central, corpus size is growing, and latency matters | Dedicated vector database |
| Answer depends on relationships, lineage, or multi-step entity connections | Knowledge graph or Graph RAG |
| Precision and recall both matter in production | Hybrid retrieval with lexical search, vector search, filters, and reranking |
If your data is structured, use direct queries and filters first.
If your content is keyword-heavy and precision-sensitive, start with search.
If your content is unstructured and your users ask natural-language questions, semantic retrieval becomes more relevant.
If your team already uses Postgres and the problem is still early, pgvector may be enough.
If semantic retrieval is central, the corpus is large, and filtering or latency requirements are growing, a dedicated vector database starts to make sense.
If relationships between entities drive the answer, explore graph-based approaches.
If you need both broad semantic matching and exact precision, a hybrid retrieval setup is usually the better production choice than pure vector search.
Common failure modes that teams misdiagnose as a vector DB problem
Many weak RAG systems fail for reasons that sit around the database, not inside it.
Weak chunking
If your answers sound vaguely relevant but miss the exact point, your chunking may be breaking context before retrieval even starts. The database can only retrieve the chunk it was given.
No metadata filters
If the system keeps returning plausible but wrong documents, you may not have enough filtering by source, date, customer, role, region, or authority level. This is one of the most common reasons production retrieval feels unreliable.
Poor query rewriting
If users ask broad, messy, or underspecified questions, raw retrieval may not be enough. Sometimes the system needs query expansion, reformulation, or decomposition before search begins. Without that step, even a strong index can underperform.
No reranking
If the right answer is somewhere in the retrieved set but rarely appears near the top, you likely have a reranking problem, not a database problem. Initial retrieval is often just candidate generation.
Treating all content as one flat corpus
If support tickets, policies, changelogs, playbooks, and API docs are all embedded and searched the same way, ranking quality usually drops. Different content types need different retrieval logic, weighting, and filtering.
Fixing these issues often improves results more than changing databases ever will.
The simplest retrieval stack that can work
A lot of engineering time gets wasted because teams start with the most fashionable setup instead of the lightest one that can do the job.
A good retrieval system does not need to look sophisticated on day one. It needs to be reliable, understandable, and aligned with the shape of the problem.
- Start with full-text search or direct queries when that is enough.
- Add semantic retrieval when you have clear evidence that lexical methods are falling short.
- Move to dedicated vector infrastructure when the workload proves you need scale, search performance, and richer filtering.
- Add graph reasoning when relationships become central to the answer.
- You do need retrieval for many AI products.
- You do not always need a vector database.
Exploring enterprise AI agents? Check out DronaHQ for your next agent
Related Articles


